
公式部分请见Github
2020.5.12
2023.4.23
前言
一份可以用于 ACM 和 OI 的模版,有问题或建议请留言QAQ
不断更新(挖坑)中
感谢付老师、小黄老师、郑老师和 QDD 的大力滋兹,Orz%%%
目录
- 2020-5-12 %版
基础
通用模版
1 |
|
性能测试
1 | //用已经AC了的题交这个代码,以测试评测机性能 |
玄学优化
1 |
|
手动扩栈
1 | //C++使用,在开头写 |
输入输出
特殊格式与转换
1 | char s[MAX]; |
精度控制
1 | //设置有效数字位数。 |
挂
1 | // 本机测试需要EOF才能看到输出结果 |
参考
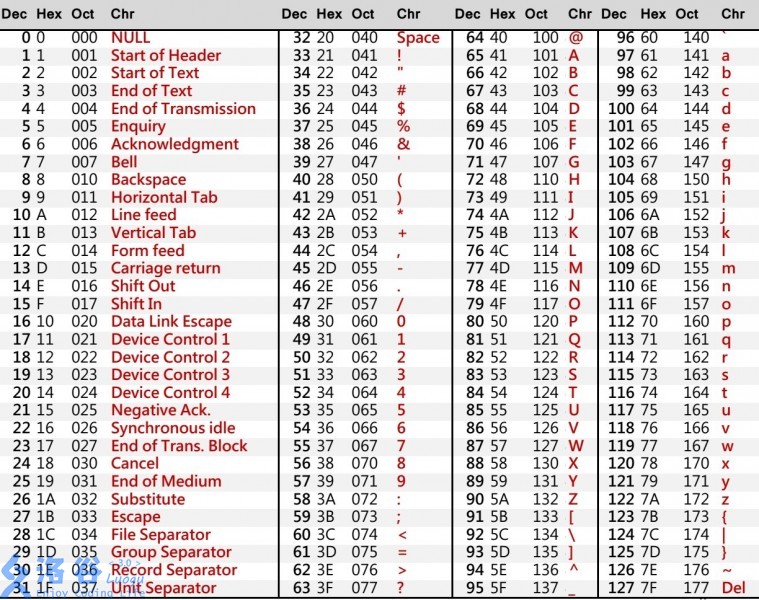
ASCII表
常用数表
| 类型 | 数据 |
|---|---|
| char | -128 ~ 127 |
| short | -32768 ~ 32767 |
| int | -2147483648 ~ 2147483647(±2e9) |
| unsigned int | -0 ~ 4294967295(4e9) |
| long long | -9223372036854775808 ~ 9223372036854775807(±9e18) |
| unsigned long long | 0 ~ 18446744073709551615(1e19) |
| double | ± (1.7e-308 ~ 1.7e308) |
| long double | ± (1.2e-4932 ~ 1.2e4932) |
| INF = 0x3f3f3f3f | 1061109567 |
| LINF = 0x3f3f3f3f3f3f3f3f | 4557430888798830399 |
时间复杂度与数据规模
评测机每秒约 $10^8$ 至 $1.5 \times 10^9$
1MB内存约 $2.5 \times 10^5$ 也就是 25万 个int(4个字节)
数学
常用网站
数学理论
负数求余
负数的求余数仍为负数,有正负时使用if (abs(x%2))或者if (x&1)判断是否为奇数
组合数
通项公式:
$$
C_{m}^{n}=\frac{m !}{n ! *(m-n) !}
$$
递推公式:
$$
C_{m}^{n}=C_{m-1}^{n}+C_{m-1}^{n-1}
$$
性质:
$$
C_{m+r+1}^{r}=\sum_{i=0}^{r} C_{m+i}^{i}
$$
$$
C_{m}^{n} * C_{n}^{r}=C_{m}^{r} * C_{m-r}^{n-r}
$$
$$
\sum_{i=0}^{m} C_{m}^{i} * x^{i}=(x+1)^{m}
$$
$$
C_{m}^{0}-C_{m}^{1}+C_{m}^{2}-\ldots \pm C_{m}^{m}=0
$$
$$
C_{m}^{0}+C_{m}^{2}+C_{m}^{4} \ldots=C_{m}^{1}+C_{m}^{3}+C_{m}^{5}+\ldots=2^{m-1}
$$
$$
C_{m+n}^{r}=C_{m}^{0} * C_{n}^{r}+C_{m}^{1} * C_{n}^{r-1}+\ldots+C_{m}^{r} * C_{n}^{0}
$$
$$
C_{m+n}^{n}=C_{m}^{0} * C_{n}^{0}+C_{m}^{1} * C_{n}^{1}+\ldots+C_{m}^{m} * C_{n}^{m}
$$
$$
n * C_{m}^{n}=m * C_{m-1}^{n-1}
$$
$$
\sum_{i=1}^{n} C_{n}^{i} * i=n * 2^{n-1}
$$
$$
\sum_{i=1}^{n} C_{n}^{i} * i^{2}=n *(n+1) * 2^{n-2}
$$
$$
\sum_{i=0}^{n}\left(C_{n}^{i}\right)^{2}=C_{2 n}^{n}
$$
奇偶性: 对于 $C_{n}^{k}$ ,若 n & k = k 则 $C_{n}^{k}$ 为奇数,否则为偶数。
错位排列数
将数字1~n排成一列,且数字i不在第i位的方案数:
$$
D_1=0\ ,\ D_2=1
$$
$$
D_n=(n-1)(D_{n-1}+D_{n-2})
$$
威尔逊定理
当且仅当p为质数时,有
$$
(p-1) ! \equiv -1 \mod{p}
$$
$$
(p-1) ! \equiv p-1 \mod{p}
$$
费马小定理
若p是质数,则对于任意整数a,有
$$
a^{p-1}\equiv 1 \mod{p}
$$
$$
a^{p}\equiv a \mod{p}
$$
费马大定理
当整数 $n>2$ 时,方程
$$
x^n+y^n=z^n
$$
无正整数解
哥德巴赫猜想
任一大于2的偶数都可写成两个素数之和
任一大于5的奇数都可写成三个素数之和
勾股数
$$
a^2+b^2=c^2
$$
当 $n>1$ 时:
$$
a=2n+1,b=2n^2+2n,c=2n^2+2n+1
$$
$$
a=2n,b=n^2-1,c=n^2+1
$$
$$
a=4n,b=4n^2-1,c=4n^2+1\ (a,b,c 互质)
$$
抽屉原理
原理一:把n+1个咕咕咕放到n个巢里,那么至少有两个咕咕咕在同一个巢里
原理二:把m*n-1个物体放入n个抽屉中,其中必定有一个抽屉中最多有m-1个物体 (例如:将3×5-1=14个物体放入5个抽屉中,则必定有一个抽屉中的物体数少于等于3-1=2)
欧拉公式
对于简单多面体(或者投射),点-边+面=2
$$
V-E+F=2
$$
欧几里德算法
最大公约数 GCD
1 | //欧几里德算法 gcd(a,b) == gcd(b,a%b) |
扩展欧几里德算法 EXGCD
裴蜀等式
对任意两个整数a和b,关于未知数x和y的线性丢番图方程(裴蜀等式):
$$
ax+by=m
$$
当且仅当m是gcd(a,b)的倍数时有整数解(x,y)。裴蜀等式有解时必然有无穷多个解。
推论:a,b互质时使得 $ax+by=1$ 有解(充要条件)
扩展欧几里德算法
用于求裴蜀等式的特解 $(x_0,y_0)$ ,即 $ax+by=gcd(a,b)$ 的解(绝对值之和最小的解)。
原式 $ax+by=m$ 的通解 k∈z
$$
x=\frac{m}{gcd(a,b)}x_0+k\frac{b}{gcd(a,b)}
$$
$$
y=\frac{m}{gcd(a,b)}y_0-k\frac{a}{gcd(a,b)}
$$
1 | //x,y为引用,返回值为gcd(a,b) |
欧拉
欧拉函数
定义
对于一个正整数x,小于x且和x互质的正整数(包括1)的个数,记作 $φ(x)$
$$
φ(x)=x\prod_{i=1}^{n}(1-\frac{1}{p_i})
$$
性质
对于质数p, $φ(p)=p-1$ ,且 $φ(1)=1$
对于质数p,有 $n=p^k$ ,则 $φ(n)=p^k-p^{k-1}=(p-1)p^{k-1}$
对于奇数p, $φ(2p)=φ(p)$
对于一个正整数n,与其互质的数之和为 $φ(n)*n/2$
对于一个正整数n,对于所有n的正整数因子d (即 $d|n$ ),即 $\sum_{d|n} φ(d)=n$
对于一个正整数n,且a为n的质因数,则:
若 $n|a$ 且 $(n/a)|a$ ,则 $φ(n)=φ(n/a)*a$
若 $n|a$ 且 $(n/a) \nmid a$,则 $φ(n)=φ(n/a)*(a-1)$
积性函数:若m,n互质(即 $gcd(m,n)=1$ ),则 $φ(mn)=φ(m)φ(n)=(m-1)(n-1)$
求法
直接求
1 | //O(sqrt()) |
线性筛法
1 | //较快,O(n) |
递推法
1 | //较慢 |
欧拉定理
若正整数a, n互质($gcd(a,p)=1$),则
$$
a^{φ(n)}\equiv1\pmod{n}
$$
欧拉降幂
对于 $x\geqφ(p)$,有
$$
a^x \equiv a^{(x \ mod \ φ(p))+φ(p)}\pmod{p}
$$
对于 $x<φ(p)$ ,无需降幂。
欧拉路径
欧拉回路
每条边只经过一次,且回到起点
- 无向图:连通(不考虑度为0的点),每个顶点度数都为偶数
- 有向图:基图连通(把边当成无向边,同样不考虑度为0的点),每个顶点的出度等于入度
- 混合图:
- 既有无向边也有向边,首先是基图连通(不考虑度为0的点),然后需要借助网络流判定。
- 首先给原图中的每条无向边随便指定一个方向(称为初始定向),将原图改为有向图G’,然后的任务就是改变G’中某些条边的方向(当然是无向边转化来的,原来混合图中的有向边不能动)使其满足每个点的入度等于出度。
- 设D[i]为G’中(点i的出度-点i的入度),即可发现,在改变G’中边的方向的过程中,任何点的D值的奇偶性都不会发生改变(设将边<i, j>改为<j, i>,则i入度加1出度减1,j入度减1出度加1,两者之差加2或者减2,奇偶性不变),而最终要求的是每个点的入度等于出度,即每个点的D值都为0,是偶数,可得:若初始定向得到的G’中任⼀个点D值是奇数,那么原图中一定不存在欧拉环。
- 若初始D值都是偶数,则将G’改装成网络:设源点S和汇点T,对于每个D[i] > 0的点i,连边<S, i>,容量为D[i]/2;对于每个D[j] < 0的点j,连边<j, T>,容量为-D[j]/2;G’中的每条边在网中仍保留,容量为i(表示该边最多只能被改变一次方向)。求这个网络的最大流,若S引出的所有边均满流,则原混合图是欧拉图,将网络中所有流量为1的中间边(就是不与S或T关联的边)在G’中改变方向,形成的新图G”一定是有向欧拉图;若S引出的边中有的没有满流,则原混合图不是欧拉图。
欧拉路径
每条边只经过一次,不要求回到起点。
- 无向图:连通(不考虑度为0的点),每个顶点度数都为偶数或者仅有两个点的度数为奇数。
- 有向图:基图连通(把边当成无向边,同样不考虑度为0的点),每个顶点出度等于入度或者有且仅有一个点的出度比入度多1,有且仅有一个点的出度比入度少1,其余的出度等于入度。
- 混合图:如果存在欧拉回路,一定存在欧拉路径,否则如果有且仅有两个点的(出度-入度)是奇数,那么给这两个点加边,判断是否存在欧拉回路,如果存在就一定存在欧拉路径。
杜教筛
1 | //积性函数,欧拉函数和莫比乌斯函数 |
扩展大步小步 Baby Steps Giant Steps
用于求解高次同余方程,即求解x:
$$
a^{x} \equiv b \mod{m}
$$
普通版要求m为质数(或者a与m互质),如果x有解,则 $0 \leq x \lt m$;扩展版无要求
下列代码数据范围 $0 \leq a, b \leq m \leq 10^9 $
1 | //北上广深算法 |
二次剩余
求二次同余方程的解 $x$ ,其中 $p$ 为奇质数:
$$
x^{2} \equiv n\ (\bmod \ p)
$$
1 | long long quick_mod(long long a, long long b, long long m) |
快速傅里叶变换 FFT
多项式乘法
1 | //计算多项式乘法F(x)*G(x) |
相同位数整数乘法
1 | /* |
任意整数乘法
1 | //较复杂 |
快速幂
1 | //O(logN) x^n |
斐波那契数列
通项:
$$
a_{1}=1, a_{2}=1, a_{n}=a_{n-1}+a_{n-2}\left(n \geq 3, n \in N^{*}\right)
$$
$$
a_{n}=1 / \sqrt{5}\left[\left(\frac{1+\sqrt{5}}{2}\right)^{n}-\left(\frac{1-\sqrt{5}}{2}\right)^{n}\right]
$$
1 | // 求第n项,模mod |
素数
试商法
1 | //试商法 |
打表法
1 | //O(n*loglogn) |
素因子
直接求
1 | // 查询数的所有不重复素因子 |
打表法
1 | // 筛每个数的最小素因子 |
逆元
定义
如果有 $a*b\equiv 1 \pmod{p}$ 且 $gcd(a,p)=1$ (a与p互质),则称b是模p意义下a的乘法逆元,记 $b=inv(a)$ 或 $b=a^{−1}$
(定义了模意义下的除法运算:除以一个数取模等于乘以这个数的逆元取模)
求法
费马小定理
由费马小定理得 $a^p-a \equiv 0 \pmod{p}$
即 $a^p \equiv a \pmod{p}$
即 $a^{p-1} \equiv 1 \pmod{p}$
即 $a*a^{p-2} \equiv 1 \pmod{p}$
当模数p为质数时, $a^{p-2}$ 即为a在模p意义下的逆元,快速幂求解即可,时间复杂度O(logn)
1 | //模数MOD为质数 |
扩展欧几里得法
1 | //扩展欧几里得法,gcd(a, MOD) = 1时有逆元 |
打表法
1 | const long long MOD = 1e9 + 7; |
中国剩余定理
孙子定理:有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?
求解同余方程组
$$
\left{\begin{array}{l}{x \equiv a_{1}\left(\bmod m_{1}\right)} \ {x \equiv a_{2}\left(\bmod m_{2}\right)} \ {x \equiv a_{3}\left(\bmod m_{3}\right)} \ {\ldots} \ {x \equiv a_{k}\left(\bmod m_{k}\right)}\end{array}\right.
$$
其中 $m_{1}, m_{2}, m_{3} \dots m_{k}$ 为两两互质的整数
求 $x$ 的最小非负整数解
解:
令 $M=\prod_{i=1}^{k} m_{i}$ ,即 $M$ 是所有 $m_i$ 的最小公倍数
$t_i$ 为 $\frac{M}{m_{i}}$ 模 $m_i$ 的逆元,即 $\frac{M}{m_{i}} t_{i} \equiv 1\left(\bmod m_{i}\right)$ 的最小非负整数解
则有一个解为 $x=\sum_{i=1}^{k} a_{i} \frac{M}{m_{i}} t_{i}$
通解为 $x+i * M(i \in Z)$
特别的,最小非负整数解为 (x%M+M)%M
1 | int china() |
整数运算
大整数
1 | //2的n次方可以用pow直接算 |
自动取模
1 | template<long long MOD> |
求N!的最后一位的非0数
1 | const int ff[] = {1, 1, 2, 6, 4, 4, 4, 8, 4, 6}; |
星期问题
基姆拉尔森公式
$$
W = (D + 2M + 3(M + 1) / 5 + Y + Y / 4 - Y / 100 + Y / 400) \mod 7
$$
1 | // 已知1752年9月3日是Sunday,并且日期控制在1700年2月28日后 |
计算几何
Pick 公式
顶点坐标均是整点的简单多边形:
面积 = 内部格点数 + 边上格点数 / 2 - 1
S = n + s / 2 - 1
(其中n表示多边形内部的点数,s表示多边形边界上的点数,S表示多边形的面积)
已知圆锥表面积S求最大体积V
$$
V = S \times \sqrt{\frac{S}{72\pi}}
$$
常用
1 | struct Point |
凸多边形宽度
1 | //平行切线间的最小距离 |
凸包,图形,交点,交线,数学,半平面交
1 |
|
二进制
状态压缩
| 最低位是第0位 | 操作 |
|---|---|
| 取第k位(非0则为1) | (n >> k) & 1 |
| 取后k位(同上,0~k-1位) | n & ((1 << k) – 1) |
| 第k位取反 | n ^= (1 << k) |
| 第k位变为1 | n |= (1 << k) |
| 第k位变为0 | n &= (~(1 << k)) |
lowbit函数
1 | //lowbit(x)是x的二进制表达式中最低位的1所对应的值 |
动态规划 DP
01背包
$$
F[i,v]=max{F[i−1,v],\ F[i−1,v−C_i]+W_i}
$$
从二维降到一维时应逆序进行
1 | //二维 |
完全背包
01背包的一维顺序版本
多重背包
二进制优化:按照2的幂进行拆分转化为01背包
二维背包
限制条件加一维
1 | for k=1 to K |
依赖背包
选主件,对附件跑01背包,最后对主件跑01背包
区间dp
石子归并
1 | F[i][j]=min{F[i][k]+F[k+1][j]}+Sum[i][j] |
四边形优化
枚举中间值时枚举一个新数组,更新时更新该数组为新的中间值
1 | for (long long i=1; i<n; i++) |
状压dp
把储存原始状态时应该用逆状态存放,判断时可以直接用&
二分
1 | //求在满足条件下最大或最小的值的题目,满足单调性和有序性 |
三分
1 | // 用于单峰函数求极值 |
数据结构
并查集
1 | // 均摊O(1)的查找、合并 |
单调栈
1 | //用途:O(n),找到从左/右遍历第一个比它小/大的元素的位置 |
区间最值查询 RMQ
1 | //用于离线区间查询最大值和最小值 |
字符串
最长回文串
1 | //Manacher算法 |
Hash处理
全字符集
1 | //ASCII全字符集,通用版,不一定完全适用 |
小写字母集
1 | const long long MAXN = 1700; //字符串长度 |
字符串匹配
KMP
1 | const int MAXN = 1000; |
扩展KMP
1 | /* |
AC自动机
快速版
1 | //适用于小写字母 |
完整版
1 | //适用字符多 |
最长上升子序列 LIS
动态规划
直接 DP 问题不大,注意一下给你的如果是个空数组就行了
对于位置 i ,dp[i] 表示以 nums[i] 结尾的 LIS 的长度
所以初始化 dp[i]=1, 1<=i<=n 毕竟每个位置自身就是长度为1的 LIS
对于位置 i ,dp[i] 一定是由前面的结尾的值小于 nums[i] 的位置转移过来的
所以 dp[i]=max(dp[j]+1), 1<=j<i, a[j]<a[i]
$O(n^2)$ 的时间, $O(n)$ 的空间,最长不降子序列加等号就行
1 | class Solution |
二分查找优化
有一个题解是这样说的,道理是这个道理,然而我不知道为什么这样是对的:
- 新建数组 cell,用于保存最长上升子序列
- 对原序列进行遍历,将每位元素二分插入 cell 中
- 如果 cell 中元素都比它小,将它插到最后
- 否则,用它覆盖掉比它大的元素中最小的那个。
- 总之,思想就是让 cell 中存储比较小的元素。这样,cell 未必是真实的最长上升子序列,但长度是对的。
当然还有一个我能理解的办法,不然我也不会写这个东西了
这个办法的核心是维护一个数组,d[i] 表示长度为 i 的 LIS 的末尾元素的最小值,初始化 d1=nums[0] 。同时维护一个变量 len 标记目前的 LIS 长度
遍历数组,对于每一个元素 nums[i]:
- 如果这个元素大于已知的最长 LIS 的末尾元素,那么我们就找到了一个更长的 LIS ,因此 len++, d[len]=nums[i]
- 否则二分查找数组 d ,找到第一个比 nums[i] 小的位置 j,j 就是这个元素前面能用的最大 LIS 长度,d[j+1] 肯定是大于nums[i] ,那么现在长度为 j+1 的 LIS 末尾元素最小值就应该是 nums[i],d[j+1]=nums[i]
这样操作数组 d 肯定是单调的,所以可以用二分查找
1 | class Solution |
后缀数组
1 | //rrank:rrank[i]为起始位置为i的后缀的排名,i:[0,len) |
编辑距离
定义
编辑距离(Edit Distance),又称 Levenshtein 距离。
编辑距离是指两个字符串之间,由一个字符串转化为另一个字符串所需的最小编辑操作次数。
许可的编辑操作包括:
- 在原串中添加一个字符
- 在原串中删除一个字符
- 在原串中修改一个字符
解法
解法当然是 DP 了!
先来看看操作,设原串为 A 新串为 B,A 串的长度为 n,B 串的长度为 m,那么现在就有对两个串的 6 种操作。
然而我们可以把操作简化为三种:
- 在 A 中添加一个字符(等价于在 B 中删除一个字符)
- 在 B 中添加一个字符(等价于在 A 中删除一个字符)
- 在 A 中修改一个字符(等价于在 B 中修改一个字符)
然后看看转移,这里用 dp[i][j] 表示 A 从头开始的 i 个字符与 B 从头开始的 j 个字符。
i 和 j 为 0 的时候就表示空串。所以这个二维数组应该开到 dp[n + 1][m + 1] 。
对于 dp[i][j] 可以由下面三种方式转移得到:
dp[i - 1][j] + 1只需要在现有 A 串的末尾添加一个字符即可dp[i][j - 1] + 1只需要在现有 B 串的末尾添加一个字符即可dp[i - 1][j - 1] + (A[i - 1] == B[i - 1] ? 0 : 1)这里需要判断 A 串中第 i 个字符(下标 i - 1)和 B 串中第 j 个字符(下标 j - 1)是否相同。相同的话直接转移,不同的话需要把 A[i - 1] 修改为 B[j - 1],因此编辑距离增加 1
因此
$$
dp[i][j]=min(dp[i-1][j]+1,dp[i][j-1]+1,dp[i][j]+(A[i - 1] == B[i - 1] ? 0 : 1))
$$
最后看看边界条件,由于空串到任意一个串只需要不断加加加,一个串到空串只需要不断减减减,所以:
dp[i][0] = i在 B 中添加 i 个字符dp[0][j] = j在 A 中添加 j 个字符
条件齐了,将 i 和 j 从 0 推到 n 和 m 即可,正推时所有前置条件都已经算完了。
时空复杂度均为 $O(nm)$。
实现
1 | class Solution |
排序
快速排序
1 | // 0下标 |
归并排序
1 | const int MAXN = 200000; |
搜索
N皇后
1 | void queen() |
BFS 队列版本
1 | typedef pair<int, int> P; //点的坐标 |
C++
引用
1 | //引用(reference)为对象起了另一个名字,将引用与初始值绑定(bind)在一起,二者类型需相同 |
范围for
1 | //C++ 11 |
列表
1 | //c++11 |
二进制读写
1 | // 将int以二进制输出(四个字节) |
头文件
< __builtin > 内建函数
1 | __builtin_clz(x) //返回x的二进制前导0的个数 |
< cmath > 数学函数
1 | //基础运算 |
< random > 随机函数
1 | mt19937 mt_rand(time(0)) //初始化随机数生成器 |
< cctype > 字符类型
1 | isalnum() //如果参数是字母或数字,该函数返回true |
< cstring > C字符串
1 | memset(a, 0, sizeof(a)) //将数组a清零,理论上只能将数组全部变成0或-1,其他数也行,原因未知 |
< algorithm > 算法
1 | swap(a, b) //交换两个变量的值。 |
< numeric > 数值序列
1 | //使用vector时应用v.begin()和v.end() |
< utility > 二元组
1 | pair<string, int> planet; //定义一个<string, int>二元组 |
< string > 字符串
1 | s.size() |
< bitset > 01数组
1 | bitset<10000> s; //定义一个10000位二进制数,<>中填写位数。 |
< iterator > 迭代器
1 | //迭代器为指针 |
< vector > 动态数组
1 | vector<vector<int>> v; //二维整型动态数组 |
< map > 映射表
1 | //map |
< set > 集合
1 | //set |
< stack > 栈
1 | stack<int> s; //定义一个int类型的栈 |
< queue> 队列
1 | //先进先出队列 |
Python
输入
1 | #存放列表 |
留坑
- 尺取法
- 威佐夫
- nim K
- 容斥原理
- 隔板法
- 斯特林数(第一类第二类)
- 矩阵快速幂
- 高斯消元
- 等价类计数
- 卡特兰数应用
- Lucas定理
- 莫比乌斯反演
- 矩阵运算
- 矩阵快速幂
- 母函数
- NTT
- 回文自动机
- 莫比乌斯 函数 反演
- 字典树
- 线段树
- 堆
1 | make_heap(v.begin(),v.end(), cmp);//创建堆,无cmp时默认大根堆 |